Note
La progettazione fisica ha per scopo produrre un progetto fisico sulla base di dati, cioè un progetto che ottenga prestazioni ottimali tramite scelta e dimensionamento di strutture fisiche di accesso.
Il progetto fisico viene eseguito in modo differente su ciascun prodotto.
Blocchi
Note
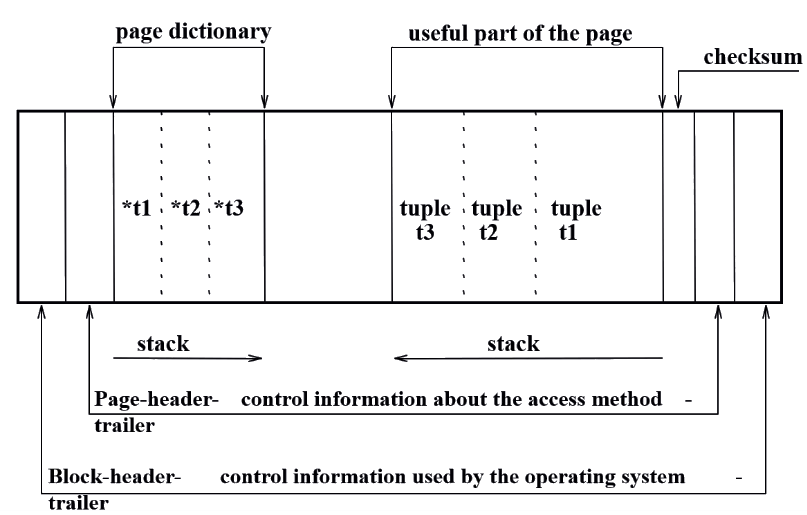
Definiamo un blocco come un’unità di accesso ad un file tramite operazione di read/write. Di questo consideriamo il block factor, che è il numero di record logici contenuti in un blocco.
Questi sono costruiti e organizzati con la seguente struttura:
Per indicare questi blocchi, si utilizza un file indice.
Un indice è una struttura ausiliaria per l’accesso efficiente alle tuple di un database. Usa come input i valori di un’attributo o di una lista di attributi, detti chiave dell’indice.
Questi possono essere unici o multipli, oppure densi o sparsi.
Struttura ad albero degli indici
Questi alberi hanno la caratteristica di avere l’ultimo livello che indicizza tutti i dati, riducendo notevolmente il costo asintotico per query ad intervalli.
In alcuni casi si può anche indicizzare usando un hashmap.
Metodi di join
Note
I join sono le operazioni più frequenti e costose. I metodi di valutazione più importanti sono:
Nested loop: Il banale doppio ciclo
for.Merge scan: Se le due tabelle sono ordinate si procede linearmente, scannerizzando parallelamente le due tabelle.
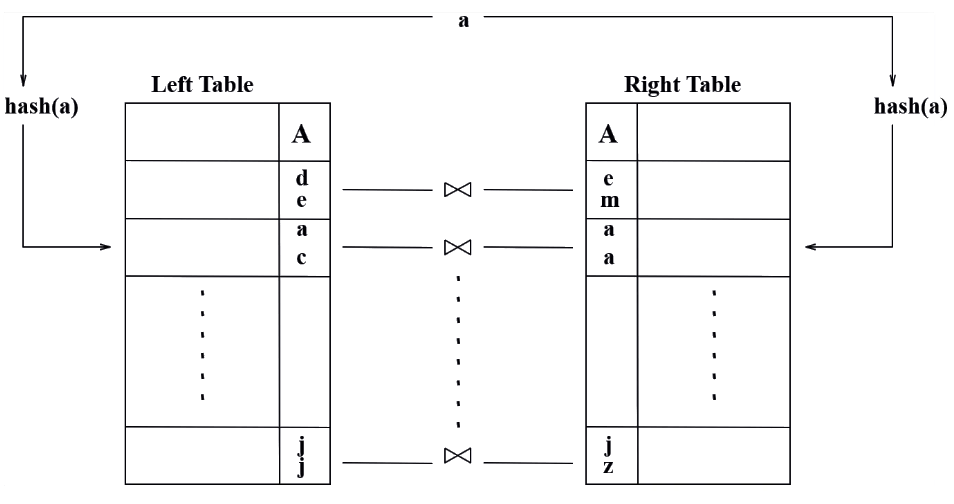
Hashed join: Se i dati sono ordinati dentro un hash, si confrontano gli hash che corrispondono, facendo all’interno un nested loop.
Design di base
Note
Di base ogni tabella ha un indice unique sulla chiave principale, vari indici unique sulle chiavi secondarie più rilevanti, e vari indici unique oppure not unique sugli attributi usati per le selezioni e i join.
Generalmente in un progetto si:
- Assegna uno unique index alle primary keys
- Assegna uno unique index alle chiavi secondarie se hanno predicati di uguaglianza
- Assegna uno not unique index agli altri attributi se hanno predicati di uguaglianza
- Assegna not unique index agli attributi di join delle relazioni che si presume sia “interne” nei join
- Fare “tuning” (aggiunta ed eliminazione di indici) manuale