SQL (Structured Query Language) è un linguaggio di usato per gestire dati principalmente in DBMS relazionali. Si compone di due parti:
Data Definition Language (DDL): definizione di domini, tabelle, indici, autorizzazioni, viste, vincoli, procedure, trigger
Data Manipulation Language (DML): linguaggio di query, modifica, e comandi transazionali
Standard SQL
Esistono diversi standard di SQL, quelli principali sono:
SQL-1: include costrutti base e integrità referenziale
SQL-2: versione più adottata tuttora
SQL-3: versione più completa, con trigger, oggetti, funzioni esterne ed estensioni per Java e XML
Di SQL-2, in particolare, si distinguono 3 livelli:
Entry SQL: più a meno equivalente a SQL-1
Intermediate SQL
Full SQL
La maggior parte dei sistemi è conforme a SQL-2 Intermediate, ed offre delle estensioni proprietarie per le funzioni avanzate.
Interrogazioni
Note
Le interrogazioni SQL sono dichiarative, quindi l’utente specifica quale informazione è di suo interesse, ma non come estrarla dai dati. Le interrogazioni sono poi tradotte dal query optimizer nel linguaggio procedurale interno al DBMS, e quindi permette al programmatore di focalizzarsi sulla leggibilità, e non sull’efficienza.
Le interrogazioni SQL hanno una sintassi:
select AttrEspr {, AttrEspr} from Tabella {, Tabella} [where Condizione]
La query effettua il prodotto cartesiano delle tabelle nella clausola from, considera solo le righe che soddisfano la condizione nella clausola where e per ogni riga valuta le espressioni nella select.
Clausola select
La clausola select ci permette di selezionare quali dati vogliamo estrarre specificamente dalle tabelle interrogate. Possiamo specificare ad esempio sole colonne, come tutte le colonne (usando *):
SELECT Nome, CCS FROM STUDENTE
Si può usare la parola chiave distinct per rimuovere duplicati:
SELECT distinct CCS FROM STUDENTE
Si possono anche usare delle funzioni, di queste notiamo ROUND(), che arrotonda valori numerici, e COUNT() che misura la cardinalità degli attributi:
SELECT ROUND(column_name, decimal_places) FROM table_nameSELECT COUNT([distinct|all] Attr) FROM table_name
Dove distinct considera una sola volta ciascun valore, e all considera tutti i valori diversi da NULL.
Per attributi numerici esistono anche funzioni SUM(), MIN(), MAX() e AVG().
Clausola where
Nella clausola where si possono inserire dei predicati sugli elementi delle tabelle, come per l’algebra relazionale abbiamo che questa è una espressione booleana di predicati semplici (P1 AND P2, P1 OR P2, NOT P1), dove i predicati semplici possono essere TRUE, FALSE o seguire la sintassi termine comparatore termine.
I comparatori sono =, <> (diverso da), <, <=, > e >=, mentre i termini possono essere costanti, attributi, o espressioni aritmetiche di esse.
-- Query che estrae tutte le colonne dagli studenti di Informatica che non abitano a BolognaSELECT * FROM Studente WHERE CCS = 'Inf' and Citta <> 'Bologna'
Esistono alcuni predicati aggiuntivi come between per le date oppure like per il pattern matching nelle stringhe.
Si nota infine che nelle tabelle possono esserci valori nulli. In SQL-1, che usa una logica a due valori un confronto con NULL restituisce FALSE, mentre in SQL-2, che usa una logica a tre valori, restituisce UNKNOWN. Esiste quindi un predicato sui valori nulli Attributo IS [NOT] NULL:
SELECT * FROM Studente WHERE Citta IS [NOT] NULL
Clausola from
Quando si specificano più tabelle nella clausola from si effettua la query su una tabella anonima con schema gli attributi delle tabelle, e istanze tutte le possibili coppie di tuple delle tabelle.
È possibile effettuare questo prodotto cartesiano usando una condizione nella clausola where:
SELECT * FROM Studente, Esame WHERE Studente.Matr = Esame.Matr
Tuttavia è possibile fare la stessa operazione usando l’operatore join equivalente:
SELECT * FROM Studente JOIN Esame ON Studente.Matr = Esame.Matr
Dove la sintassi del predicato è un espressione congiuntiva di predicati semplici AttrTab1 comparatore AttrTab2.
SELECT DISTINCT Studente.Matr, Nome FROM Studente JOIN Esame ON Studente.Matr = Esame.Matr WHERE CCS = 'Ges' AND Voto = 30
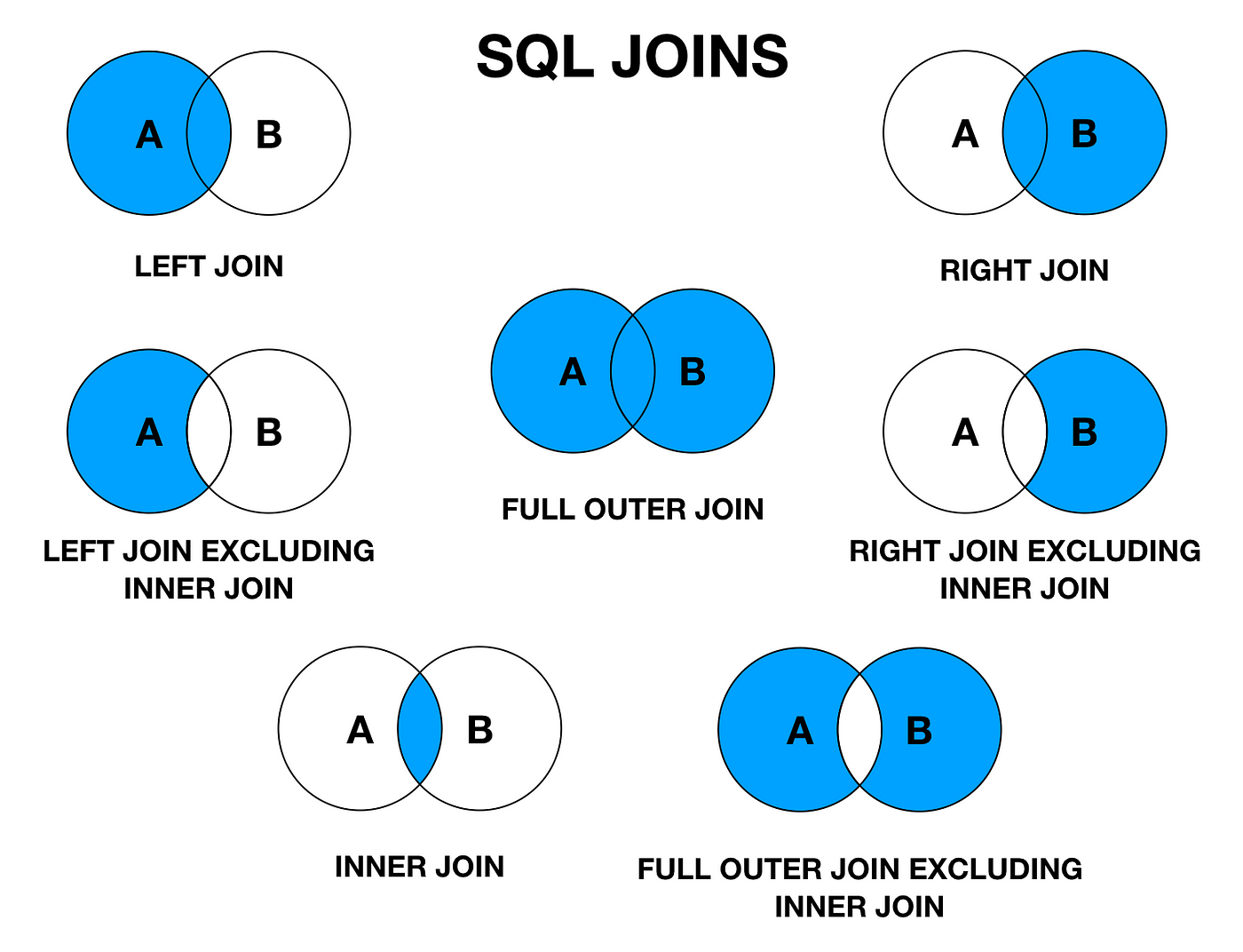
Esistono diversi tipi di JOIN, tra cui INNER (predefinito), RIGHT [OUTER], LEFT [OUTER] e FULL [OUTER].
Clausola order by
La clausola order by compare in coda all’interrogazione, e ordina le righe del risultato.
SELECT * FROM Studente ORDER BY Cognome ASC, Nome ASC
Definizione degli schemi
Note
Uno schema è una collezione di oggetti (domini, tabelle, indici, asserzioni, viste, privilegi) che ha un nome e un proprietario.
La sua definizione in SQL-2 non è tipicamente in uso nei sistemi, però ha sintassi
I domini specificano i valori ammissibili per gli attributi, ne esistono due categorie: elementari (built-in) e definiti dall’utente.
I domini elementari principali sono:
Caratteri: questi possono essere singoli o stringhe di lunghezza variabile. Possono usare una famiglia di caratteri diversa da quella di default:
character [varying] [(lunghezza)] [character set famigliaCaratteri]
Ne esistono alternative compatte come char e varchar.
Bit: sono valori booleani, singoli o in sequenza di lunghezza variabile:
bit [varying] [(lunghezza)]
Domini numerici esatti: sono valori esatti, interi o con una parte razionale, ne esistono 4 alternative:
Domini numerici approssimati: sono valori reali approssimati, che si basano sulla rappresentazione a virgola mobile:
float [(precisione)]realdouble precision
Istanti temporali: ammettono i campi:
date --campi: month, day, yeartime [(precisione)] [with time zone] --campi: hour, minute, secondtimestamp [(precisione)] [with time zone] -- con timezone si hanno due ulteriori campi timezone_hour e timezone_minute
Intervalli temporali: questi hanno unità di tempo che si dividono in due gruppi: year, month e day,hour,minute,second.
Altri domini semplici: In SQL-3 sono stati introdotti domini come Boolean, Bigint, BLOB, CLOB, e altri costruttori (REF, ARRAY, ROW) che vanno oltre il modello relazionale.
Si possono inoltre creare domini definiti dall’utente con la sintassi
CREATE DOMAIN NomeDominio as DominioElementare [default ValoreDefault] [Constraints]
Ricordiamo che NULL è un valore polimorfico (appartiene a tutti i domini) col significato di valore non noto.
Tabelle
Una tabella SQL consiste di un insieme ordinato di attributi ed un insieme di vincoli. Per creare una tabella si usa la sintassi:
I vincoli sono delle condizioni che devono essere verificate da ogni istanza della base di dati. Si classificano in vincoli intra-relazionali e inter-relazionali.
I vincoli intra-relazionali principali sono:
not null (solo su un attributo)
primary key (implica not null, può essere indicato per un solo attributo dopo il dominio, o per più attributi in coda alla definizione primary key(Attributo {, Attributo}))
unique (chiavi candidate, sintassi come per primary key)
check (rappresenta predicati generici)
Modifica degli schemi
Si può modificare gli oggetti degli schemi usando i comandi alter e drop.
Il comando alter si applica su domini e tabelle e modifica il loro contenuto:
ALTER TABLE Ordine ADD COLUMN NumFatt CHAR(6) ALTER COLUMN Importo ADD DEFAULT 0 DROP COLUMN Data
Il comando drop si applica su domini, tabelle, indici, view, asserzioni, procedure e trigger, e cancella oggetti:
DROP TABLE Ordine
Al drop si possono aggiungere le opzioni restrict (impedisce drop se gli oggetti comprendono istanze) e cascade (applica drop agli oggetti collegati).
Cataloghi relazionali
Un catalogo contiene il dizionario dei dati, cioè la descrizione relazionale della struttura dei dati contenuti nel database. Lo standard SQL-2 lo organizza su due livelli:
Definition_Schema: insieme di tabelle che contengono la descrizione di tutte le strutture della base di dati
Information_Schema: insieme di viste sul Definition_Schema
Il catalogo è normalmente riflessivo (ogni struttura del catalogo è descritta nel catalogo stesso), e quindi ogni comando DDL viene realizzato da opportuni comandi DML che operano sul catalogo della base di dati. Tuttavia il catalogo non deve mai essere modificato direttamente.
Integrità referenziale
Quando vengono eseguiti aggiornamenti di attributi riferiti, o cancellazioni di tuple, possono introdursi violazioni di integrità. Pertanto si introduce un meccanismo di reazione, che opera sulla tabella interna, in seguito a modifiche alla tabella esterna.
Le reazioni sono:
cascade: propaga la modifica
set null: annulla l’attributo che fa riferimento
set default: assegna il valore di default all’attributo
no action: impedisce che la modifica possa avvenire
Per quanto riguarda l’integrità referenziale gli attributi descritti come foreign key nella tabella figlio devono presentare valori presenti come valori di chiave nella tabella padre, usando le parole chiave:
references per un solo attributo, dopo il dominio
foreign key(Attributo {, Attributo}) references ... per più attributi
CREATE TABLE Esame ( Matr char(6) references Studente on delete cascade on update cascade, -- ...)
Indici
Gli indici sono meccanismi di accesso efficiente ai dati. Per crearli si usa la sintassi:
CREATE [UNIQUE] INDEX IndexName ON TableName(AttributeList)
Interrogazioni avanzate
Query Binarie
È possibile effettuare interrogazioni binarie, costruite concatenando due query SQL tramite operatori insiemistici:
Questa operazione elimina i duplicati, a meno che non venga usata l’opzione all.
Query con raggruppamento
Nelle interrogazioni si possono applicare gli operatori aggregati a sottoinsiemi di righe, aggiungendo le clausole group by e having.
-- Estrarre la somma degli importi degli ordini successivi al 10-6-24 per quei clienti che hanno emesso almeno 2 ordiniSELECT CodCli, sum(Importo) FROM Ordine WHERE Data > 10-6-24 GROUP BY CodCli HAVING count(*) >= 2
È possibile avere più raggruppamenti, che restituiranno il prodotto cartesiano tra loro.
Inoltre si nota che soltanto i predicati che richiedono la valutazione di funzioni aggregate (count, sum, min, max e avg) dovrebbero comparire nell’argomento della clausola having.
Query con insiemi
È possibile nelle clausole where e having operare con degli insiemi, con la sintassi:
AttrExpr operator <any|all> Set
Dove any indica che il predicato è vero se almeno un valore nel Set soddisfa il confronto, e all indica che il predicato è vero se tutti i valori nel Set soddisfano il confronto.
SELECT * FROM Esame WHERE voto = any(25,27,30)
Questo meccanismo ci permette anche di fare query nidificate, confrontando un attributo con il risultato di una query SQL.
-- Estrae i prodotti ordinati assieme al prodotto avente codice 'ABC'SELECT DISTINCT CodProd FROM Dettaglio WHERE CodProd <> 'ABC' and CodOrd = ANY( SELECT CodOrd FROM Dettaglio WHERE CodProd = 'ABC' )
Le query nidificate permettono anche gli operatori in e not in, che indicano rispettivamente l’appartenenza o la non appartenenza ad un insieme.
Inoltre, il confronto con una query nidificata può coinvolgere più di un attributo, racchiudendo gli attributi in un paio di parentesi tonde.
-- Estrazione di omonimiSELECT * FROM Persona P WHERE (Nome, Cognome) in ( SELECT Nome, Cognome FROM Persona P1 WHERE P1.CodFisc <> P.CodFisc )
Infine è possibile anche usare il quantificatore esistenziale exists, che indica che il predicato è vero se la query restituisce un risultato non nullo.
Viste
Note
Le viste permettono di visualizzare tabelle virtuali, usate per formulare query complesse, usando la sintassi:
CREATE VIEW NomeVista [(ListaAttributi)] AS SelectSQL
È possibile creare viste in cascata.
Comandi di modifica
Note
Per la modifica delle istanze SQL ci fornisce istruzioni per l’inserimento, cancellazione e modifica degli attributi. Tutte queste possono operare su un insieme di tuple.
Nell’inserimento l’ordine degli attributi e dei valori è significativo. Se la ListaAttributi viene omessa, si considerano tutti gli attributi della relazione. Inoltre, se la ListaAttributi non contiene tutti gli attributi della relazioni, a quelli rimanenti si assegna il valore di default o NULL.
INSERT INTO NomeTabella[(ListaAttributi)] <VALUES (listaDiValori)|SelectSQL>
Per le cancellazioni si usa la sintassi (se la condizione è omessa si cancellano tutte le tuple):
DELETE FROM NomeTabella [WHERE Condizione]
Infine, per le modifiche si usa la sintassi:
UPDATE NomeTabella SET Attributo = <Espressione|SelectSQL|NULL|default> {, SET Attributo = <Espressione|SelectSQL|NULL|default> } [WHERE Condizione]
Controllo dell’accesso
Note
Si ha che ogni componente dello schema può essere protetto. Per accedere a questi elementi il proprietario di una risorsa assegna privilegi agli altri utenti. Di base un utente predefinito _system rappresenta l’amministratore di sistema e ha pieno accesso a tutte le risorse.
Un privilegio è caratterizzato da:
La risorsa
L’utente che concede il privilegio
L’utente che riceve il privilegio
L’azione che viene consentita sulla risorsa
La possibilità di passare il privilegio ad altri utenti
SQL offre sei tipi di privilegi: insert, update, delete, select, references, usage, e all privileges che li riassume tutti.
Per concedere un privilegio:
GRANT <Privilegi|ALL PRIVILEGES> ON Risorsa TO Utenti [WITH GRANT OPTION]
Dove grant option specifica se deve essere garantita la possibilità di propagare il privilegio ad altri utenti.
Per revocare un privilegio
REVOKE Privilegi ON Risorsa FROM Utenti [RESTRICT|CASCADE]
Vincoli nel DDL
Note
Per assicurare la qualità dei dati (correttezza, completezza e attualità) si usano delle regole di integrità, e si manipolano i dati tramite programmi predefiniti.
Per quanto riguarda i vincoli di integrità generici, questi devono essere predicati che devono essere sempre veri se le istanze sono corrette. Possono essere espressi in due modi: negli schemi delle tabelle o come asserzioni separate.
Negli schemi delle tabelle si può usare la clausola check per vincoli arbitrari, con sintassi check (Condizione), dove Condizione è tutto quello che può apparire in una clausola where.
CREATE TABLE Impiegato ( -- ... Superiore character(6) check ( Matr LIKE "1%" OR Dipart = ( SELECT Dipart FROM Impiegato I WHERE I.Matr = Superiore ) ))
Al di fuori delle tabelle si possono definire asserzioni, che associano un nome ad una clausola check, con sintassi:
Immediata: la loro violazione annulla l’ultima modifica
Differita: la loro violazione annulla l’intera transazione
Di base ogni vincolo è di tipo immediate, tuttavia si può modificare il tipo iniziale dei vincoli con la sintassi:
SET CONTRAINTS <IMMEDIATE|DEFERRED>
Transazioni
Note
Le transazioni sono un’unità elementare di esecuzione incapsulata all’interno dei comandi begin transaction e end transaction, al cui interno, è previsto venga eseguito una volta sola uno dei comandi tra commit work e rollback work.
BEGIN TRANSACTION; UPDATE Account SET Balance = Balance + 10 WHERE AccNum = 12202; UPDATE Account SET Balance = Balance - 10 WHERE AccNum = 42177; SELECT Balance INTO A FROM Account WHERE AccNum = 42177; if (A >= 0) THEN COMMIT WORK ELSE ROLLBACK WORK;END TRANSACTION;
Le transazioni devono seguire le proprietà ACID:
Atomicità: La transazione deve essere atomica dallo stato iniziale a quello finale
Consistenza: Una transazione deve rispettare i vincoli di integrità
Isolamento: Una transazione non è influenzata dal comportamento delle altre transazioni concorrenti
Durabilità: L’effetto delle transazioni che hanno fatto “commit” non verrà mai perso
Procedure
Note
Le procedure sono moduli di programma che svolgono una specifica attività di manipolazione dei dati. SQL-2 permette la definizione di procedure, ma in forma molto limitata, infatti sono poi estese da sistemi proprietari, ottenendo un linguaggio di programmazione completo.
La procedura si specifica in questo modo:
PROCEDURE Nome ({, Nome Dominio}) IS BEGIN -- codiceEND;
L’uso delle procedure permette la decomposizione modulare delle applicazioni, aumentando l’efficienza, il controllo e il riuso.
Stored Procedure in MySQL
Una stored procedure è un blocco di codice SQL salvato nel database, utilizzato per automatizzare operazioni ripetitive.
Di base ha la sintassi:
DELIMITER $$CREATE PROCEDURE Nome_Procedura({, <IN|OUT|INOUT> NomeParametro Dominio})BEGIN -- Codice SQLEND $$DELIMITER;-- Chiamata alla proceduraCALL Nome_Procedura(...);-- Cancellazione proceduraDROP PROCEDURE IF EXISTS Nome_Procedura;
Si possono passare parametri alla procedure, in ingresso IN usando parametri fissi, in uscita OUT con sintassi:
DELIMITER $$CREATE PROCEDURE contaCitta(OUT totale INT)BEGIN SELECT COUNT(*) INTO totale FROM City;END $$DELIMITER;CALL contaCitta(@risultato);SELECT @risultato;
Il parametro di tipo INOUT è sia di ingresso che di uscita.
All’interno delle procedure è possibile dichiarare variabili locali:
DECLARE nome_variabile DOMINIO [DEFAULT valore];
Inoltre, si possono usare costrutti come IF e WHILE, con la sintassi:
IF condizione THEN SELECT 'Vero';ELSE SELECT 'Falso';END IF;WHILE codizione DO -- Codice SQLEND WHILE;